
Introduction to Partitioning Spatial Data using SQL Server
With the rise of remote sensors like satellites and drones, or open data world-scale projects like OpenStreetMap, datasets are becoming quite large, challenging our storage and processing systems.
One area which appears to have limited implementation is the use of partitioned tables and processing for large scale spatial data.
The pros and cons of partitioning can be found via a suitable search of the Internet. Here is one such article.
This article presents a method for partitioning OpenStreetMap Point of Interest (POI) data that uses the variable density of the data (more in big cities, less in country) to construct partitions that are more “balanced” in terms of numbers of features.
Partitioning Spatial Data
A single partition of a database table holds a homogeneous collection of data.
The most common non-spatial partitioning methodology is datetime based partitioning where a partition may hold a specific day, week, or month’s worth of data.
What can be done for spatial data?
A common method is to construct a homogeneous grid (where all grid squares are the same size) and then place all the spatial objects within each grid (box/partition) it falls within.
However, spatial data is heavily co-located which leads to the grid cell contents being highly unbalanced; and, possibly, empty cells that contain no data.
A quote from the PostGIS User Discussion Email List (Lars Aksel Opsahl) describes the experience of one practitioner:
“We use a lot of grids, but we have seen that using content to influence each grid cell size is more important than having regular sized grid cell. For instance, smaller cell’s where it’s high density of polygons and larger cell in other areas. When grid cells are “equal” related to content (and not spatial size) it also easier to run thing parallel without running into memory problems and so on.”
Spatial data conforms to Waldo Tobler’s “First Rule of Geography”:
“everything is related to everything else, but near things are more related than distant things.”
Thus spatial data, like the OSM POIs are highly spatially auto-correlated. So, POIs in a city are more dense than POIs in the country.
Loading the POI data
The Australian POI (or any other countries’ POI data) can be loaded using ogr2ogr as in the following example:
ogr2ogr -append -progress -skipfailures -a_srs "EPSG:4326" ^
-f "MSSQLSpatial" MSSQL:"server=localhost\gisdb;database=partdb;trusted_connection=yes;" ^
"\temp\pois\gis_osm_pois_free_1.shp ^
-nln dbo.osm_pois ^
-lco SCHEMA=dbo ^
-lco LAUNDER=YES ^
-lco FID=ID ^
-lco GEOMETRY_NAME=geog4326 ^
-lco GEOM_TYPE=geography ^
-nlt POINT ^
-lco SRID=4326 ^
-lco DIM=2 ^
-lco SPATIAL_INDEX=YES
The result (note the variable density of the point data) looks like this:

QuadTree Based Partitioning
So, what we need is a partitioning method that uses “content to influence each grid cell size”.
Instead of a regular gridding of space, a QuadTree decomposition of space will allow us to use “content to influence each grid cell size”. With a QuadTree, space is “tesselated” starting with a single rectangle (a “tessera”) that covers all the data. The initial rectangle is divided into four cells. Each cell is used to query the underlying data. If the content of a cell exceeds a defined amount (eg 10,000 features), that cell is again decomposed into four cells and each cell queried in the same manner. Thus cells with large feature counts are decomposed into a hierarchy of child cells until each cell contains less than or equal to the defined amount.
This is a recursive algorithm that results in the following “gridding” of our Australian POIs:

QuadTree Function
I have written a QuadTree function for SQL Server Spatial that is described by the following documentation extract (note that the function processes both geometry and geography data — the POI data is geography data):
Procedure dbo.STQuadTree(
@p_SearchOwner Varchar(250),
@p_SearchTable VARCHAR(250),
@p_SearchColumn VARCHAR(250),
@p_LL geometry,
@p_UR geometry,
@p_TargetOwner Varchar(250),
@p_TargetTable varchar(250),
@p_TargetColumn VARCHAR(250),
@p_MaxQuadLevel integer,
@p_MaxCount integer
)
DESCRIPTION
Recursively tesselates the two-dimensional space defined by @p_SearchTable using a quad tree algorithm based on a set of criteria:
1. Depth of the Quad Tree;
2. Max number of features per quad
(If number in a quad is > max number, quad is divided into four with each being processed, possibly recursively)
The output polygons representing the quads that contain the data
are written to the @p_TargetTable with some specific fields
PARAMETERS
@p_SearchOwner - Varchar(250) - Schema owner of @p_SearchTable table
@p_SearchTable - VARCHAR(250) - Name of table in @p_SchemaOwner that is to be quadded
@p_SearchColumn - VARCHAR(250) - Geometry column in @p_SearchTable containing spatial data to be quadded.
@p_LL - geometry - Lower Left corner of extent of data in @p_SearchColumn to be quadded (normally LL of extent of all data in @p_searchColumn)
@p_UR - geometry - Upper Right corner of extent of data in @p_SearchColumn to be quadded (normally UR of extent of all data in @p_searchColumn)
@p_TargetOwner - Varchar(250) - Schema owner of @p_TargetTable
@p_TargetTable - varchar(250) - Name of table that will be created and will hold the quad tree rectangles.
@p_TargetColumn - VARCHAR(250) - Name of geometry column in @p_TargetTable that will hold resultant quad rectangles.
@p_MaxQuadLevel - integer - Maximum depth to recurse.
@p_MaxCount - integer - Max number of features per quad tree rectangle.
This can be used to tesselate our Australian POIs as follows:
The function ships with the package of TSQL functions available via the shop on this website.
DECLARE @LL geometry = geometry::STGeomFromText('POINT(111.43 -44.43)',4326);
DECLARE @UR geometry = geometry::STGeomFromText('POINT(154.13 -8.28)',4326);
EXEC dbo.STQuadTree /*@p_SearchOwner*/ 'dbo',/*@p_SearchTable*/ 'osm_pois',/*@p_SearchColumn*/ 'geog4326',
/*@p_LL*/ @LL,/*@p_UR*/ @UR,
/*@p_TargetOwner*/ 'dbo',/*@p_TargetTable*/ 'osm_pois_q',/*@p_TargetColumn*/ 'geog4326',
/*@p_MaxQuadLevel*/ 16,/*@p_MaxCount*/ 2500;
GO
-- Count quad buckets as this is the number of partitions we want (plus 1)
SELECT COUNT(*) FROM dbo.osm_pois_q;
GO
-- 244
See image above.
Using QuadTree Cells to Define Partitions
Now that balanced QuadTree cells have been created, we will use them to create a partitioning schema for the OSM POI data.
(This is not a lesson for understanding the “nuts and bolts” of SQL Server partitioning. There are lots of tutorials and documentation available for that. What follows is simply a specific implementation for the POI data to prove the concept of spatial data partitioning.)
1. Create Filegroups one per quadid and an additional one at the end.
SELECT 'ALTER DATABASE PARTDB ADD FILEGROUP FGQUAD' + cast(a.quad_id as varchar(10)) + ';' FROM dbo.osm_pois_q as a UNION ALL SELECT 'ALTER DATABASE PARTDB ADD FILEGROUP FGQUAD999;' GO -- Example result ALTER DATABASE PARTDB ADD FILEGROUP FGQUAD1; ALTER DATABASE PARTDB ADD FILEGROUP FGQUAD2; ... ALTER DATABASE PARTDB ADD FILEGROUP FGQUAD999;
The whole result set is copied and pasted into a new query window and executed.
2. Create data files for each filegroup
SELECT 'ALTER DATABASE PARTDB ADD FILE ( NAME = DATFGQUAD' + CAST(a.quad_id as varchar(10)) + ', FILENAME = ''F:\SQL Server\databases\PARTDB\DATFGQUAD' + CAST(a.quad_id as varchar(10)) + '.ndf'', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP FGQUAD' + CAST(a.quad_id as varchar(10)) + ';' FROM dbo.osm_pois_q as a UNION ALL SELECT 'ALTER DATABASE PARTDB ADD FILE ( NAME = DATFGQUAD999, FILENAME = ''F:\SQL Server\databases\PARTDB\DATFGQUAD999.ndf'', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP FGQUAD999;' GO -- Example result ALTER DATABASE PARTDB ADD FILE ( NAME = DATFGQUAD1, FILENAME = 'F:\SQL Server\databases\PARTDB\DATFGQUAD1.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP FGQUAD1; ALTER DATABASE PARTDB ADD FILE ( NAME = DATFGQUAD2, FILENAME = 'F:\SQL Server\databases\PARTDB\DATFGQUAD2.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP FGQUAD2; ... ALTER DATABASE PARTDB ADD FILE ( NAME = DATFGQUAD999, FILENAME = 'F:\SQL Server\databases\PARTDB\DATFGQUAD999.ndf', SIZE = 5MB, MAXSIZE = 100MB, FILEGROWTH = 5MB) TO FILEGROUP FGQUAD999;
Again, the whole result set is copied and pasted into a new query window and executed.
3. Create Partition Function
-- Generate values SELECT STRING_AGG(CAST(a.quad_id as varchar(10)),',') as vals FROM dbo.osm_pois_q as a; GO vals 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240,241,242,243,244 -- Paste resultant "vals" into VALUES clause of function. CREATE PARTITION FUNCTION QUADPF (int) AS RANGE LEFT FOR VALUES (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240,241,242,243,244); GO
4. Create Partition Scheme over filegroups
select STRING_AGG('FGQUAD' + CAST(a.quad_id as varchar(10)),',') + ',FGQUAD999' as fgs
FROM dbo.osm_pois_q as a
GO
-- fgs
-- FGQUAD1,FGQUAD2,FGQUAD3,FGQUAD4,FGQUAD5,FGQUAD6,...,FGQUAD244,FGQUAD999
-- Copy fgs string to partition list of partition scheme.
CREATE PARTITION SCHEME QUADPS
AS PARTITION QUADPF
TO (FGQUAD1,FGQUAD2,FGQUAD3,FGQUAD4,FGQUAD5,FGQUAD6,FGQUAD7,FGQUAD8,FGQUAD9,FGQUAD10,FGQUAD11,FGQUAD12,FGQUAD13,FGQUAD14,FGQUAD15,FGQUAD16,FGQUAD17,FGQUAD18,FGQUAD19,FGQUAD20,FGQUAD21,FGQUAD22,FGQUAD23,FGQUAD24,FGQUAD25,FGQUAD26,FGQUAD27,FGQUAD28,FGQUAD29,FGQUAD30,FGQUAD31,FGQUAD32,FGQUAD33,FGQUAD34,FGQUAD35,FGQUAD36,FGQUAD37,FGQUAD38,FGQUAD39,FGQUAD40,FGQUAD41,FGQUAD42,FGQUAD43,FGQUAD44,FGQUAD45,FGQUAD46,FGQUAD47,FGQUAD48,FGQUAD49,FGQUAD50,FGQUAD51,FGQUAD52,FGQUAD53,FGQUAD54,FGQUAD55,FGQUAD56,FGQUAD57,FGQUAD58,FGQUAD59,FGQUAD60,FGQUAD61,FGQUAD62,FGQUAD63,FGQUAD64,FGQUAD65,FGQUAD66,FGQUAD67,FGQUAD68,FGQUAD69,FGQUAD70,FGQUAD71,FGQUAD72,FGQUAD73,FGQUAD74,FGQUAD75,FGQUAD76,FGQUAD77,FGQUAD78,FGQUAD79,FGQUAD80,FGQUAD81,FGQUAD82,FGQUAD83,FGQUAD84,FGQUAD85,FGQUAD86,FGQUAD87,FGQUAD88,FGQUAD89,FGQUAD90,FGQUAD91,FGQUAD92,FGQUAD93,FGQUAD94,FGQUAD95,FGQUAD96,FGQUAD97,FGQUAD98,FGQUAD99,FGQUAD100,FGQUAD101,FGQUAD102,FGQUAD103,FGQUAD104,FGQUAD105,FGQUAD106,FGQUAD107,FGQUAD108,FGQUAD109,FGQUAD110,FGQUAD111,FGQUAD112,FGQUAD113,FGQUAD114,FGQUAD115,FGQUAD116,FGQUAD117,FGQUAD118,FGQUAD119,FGQUAD120,FGQUAD121,FGQUAD122,FGQUAD123,FGQUAD124,FGQUAD125,FGQUAD126,FGQUAD127,FGQUAD128,FGQUAD129,FGQUAD130,FGQUAD131,FGQUAD132,FGQUAD133,FGQUAD134,FGQUAD135,FGQUAD136,FGQUAD137,FGQUAD138,FGQUAD139,FGQUAD140,FGQUAD141,FGQUAD142,FGQUAD143,FGQUAD144,FGQUAD145,FGQUAD146,FGQUAD147,FGQUAD148,FGQUAD149,FGQUAD150,FGQUAD151,FGQUAD152,FGQUAD153,FGQUAD154,FGQUAD155,FGQUAD156,FGQUAD157,FGQUAD158,FGQUAD159,FGQUAD160,FGQUAD161,FGQUAD162,FGQUAD163,FGQUAD164,FGQUAD165,FGQUAD166,FGQUAD167,FGQUAD168,FGQUAD169,FGQUAD170,FGQUAD171,FGQUAD172,FGQUAD173,FGQUAD174,FGQUAD175,FGQUAD176,FGQUAD177,FGQUAD178,FGQUAD179,FGQUAD180,FGQUAD181,FGQUAD182,FGQUAD183,FGQUAD184,FGQUAD185,FGQUAD186,FGQUAD187,FGQUAD188,FGQUAD189,FGQUAD190,FGQUAD191,FGQUAD192,FGQUAD193,FGQUAD194,FGQUAD195,FGQUAD196,FGQUAD197,FGQUAD198,FGQUAD199,FGQUAD200,FGQUAD201,FGQUAD202,FGQUAD203,FGQUAD204,FGQUAD205,FGQUAD206,FGQUAD207,FGQUAD208,FGQUAD209,FGQUAD210,FGQUAD211,FGQUAD212,FGQUAD213,FGQUAD214,FGQUAD215,FGQUAD216,FGQUAD217,FGQUAD218,FGQUAD219,FGQUAD220,FGQUAD221,FGQUAD222,FGQUAD223,FGQUAD224,FGQUAD225,FGQUAD226,FGQUAD227,FGQUAD228,FGQUAD229,FGQUAD230,FGQUAD231,FGQUAD232,FGQUAD233,FGQUAD234,FGQUAD235,FGQUAD236,FGQUAD237,FGQUAD238,FGQUAD239,FGQUAD240,FGQUAD241,FGQUAD242,FGQUAD243,FGQUAD244,FGQUAD999);
GO
5. Create partitioned table using partition scheme
CREATE TABLE [dbo].[osm_poi](
[id] [int] IDENTITY(1,1) NOT NULL,
[osm_id] [varchar](20) NULL,
[code] [numeric](4, 0) NULL,
[fclass] [varchar](28) NULL,
[name] [varchar](1000) NULL,
[geog4326] [geography] NULL,
[quadid] [int] NOT NULL,
CONSTRAINT [osm_poi_pk] PRIMARY KEY CLUSTERED ([id] ASC,[quadid] ASC)
)
ON QUADPS (quadid);
GO
-- Add spatial constraints to limit geog4326 to points
ALTER TABLE [dbo].[osm_poi] WITH CHECK
ADD CONSTRAINT [osm_pois_srid_point_ck]
CHECK ([geog4326] IS NULL OR [geog4326].STGeometryType()='Point')
GO
-- Add spatial constraints to limit geog4326 Srid to 4326
ALTER TABLE [dbo].[osm_poi] WITH CHECK
ADD CONSTRAINT [osm_pois_srid_4326_ck]
CHECK ([geog4326] IS NULL OR [geog4326].[STSrid]=4326)
GO
6. Create QuadId Function to assign quadid to each point record in osm_poi
DROP FUNCTION IF EXISTS [dbo].[GetQuadId];
GO
CREATE Function [dbo].[GetQuadId]( @p_geog geography )
Returns Integer
As
Begin
Declare
@v_qid integer;
IF ( @p_geog is null OR @p_geog.STIsEmpty()=1 )
RETURN NULL;
-- Use NN query to ensure assignment of all points to a quad bucket
DECLARE c_quad
CURSOR READ_ONLY
FOR SELECT TOP 1
a.quad_id
FROM [dbo].[osm_pois_q] as a
WHERE a.geog4326.STDistance(@p_geog) is not null
ORDER BY a.geog4326.STDistance(@p_geog);
OPEN c_quad;
FETCH NEXT
FROM c_quad
INTO @v_qid;
CLOSE c_quad;
DEALLOCATE c_quad;
RETURN @v_qid;
End;
GO
-- Test function
select [dbo].[GetQuadId] ( geography::Point(-41.01562500, 145.73437500, 4326 ) ) as quadid;
GO
-- quadid
-- 60
-- Check all points will be assigned to a quad tree bucket (expect result of 0)
select count(*) as count from dbo.osm_pois as a where dbo.GetQuadId(a.geog4326) is null;
GO
-- count
-- 0
[code type="sql"]
<h3>7. Now insert data from osm_pois table which contains imported OSM POI Shapefile data</h3>
[code type="sql"]
INSERT INTO [dbo].[osm_poi] (
[osm_id],
[code],
[fclass],
[name],
[geog4326],
[quadid]
)
SELECT [osm_id],
[code],
[fclass],
[name],
[geog4326],
[dbo].[GetQuadId]([geog4326])
FROM [dbo].[osm_pois];
GO
-- What did quad tree code discover as the maximum feature count across all quadtree cells?
SELECT max(feature_count) as row_count from dbo.osm_pois_q as a;
GO
-- row_count
-- 2416
-- What does the SQL Server metadata tables tell us the maximum row (feature) count?
SELECT TOP 1 partition_id, row_count
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID('dbo.osm_poi')
ORDER BY row_count desc;
GO
--partition_id row_count
--72057594103005184 2416
-- Comparing both row_counts shows they are the same (as required)
-- Build Spatial Index
CREATE SPATIAL INDEX [osm_poi_sx]
ON [dbo].[osm_poi]([geog4326])
USING GEOGRAPHY_AUTO_GRID
WITH (CELLS_PER_OBJECT = 16, PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
Conduct some Tests
1. Query using partition assignment function
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326);
set statistics time on
select count(*) as count
from dbo.osm_poi as a
where quadid = [dbo].[GetQuadId] (@sGeog);
set statistics time off
GO
-- count
-- 1528
-- SQL Server Execution Times: CPU time = 548437 ms, elapsed time = 549059 ms.
Note that it doesn’t prune the partitions considering all 245 partitions; it is also quite slow.
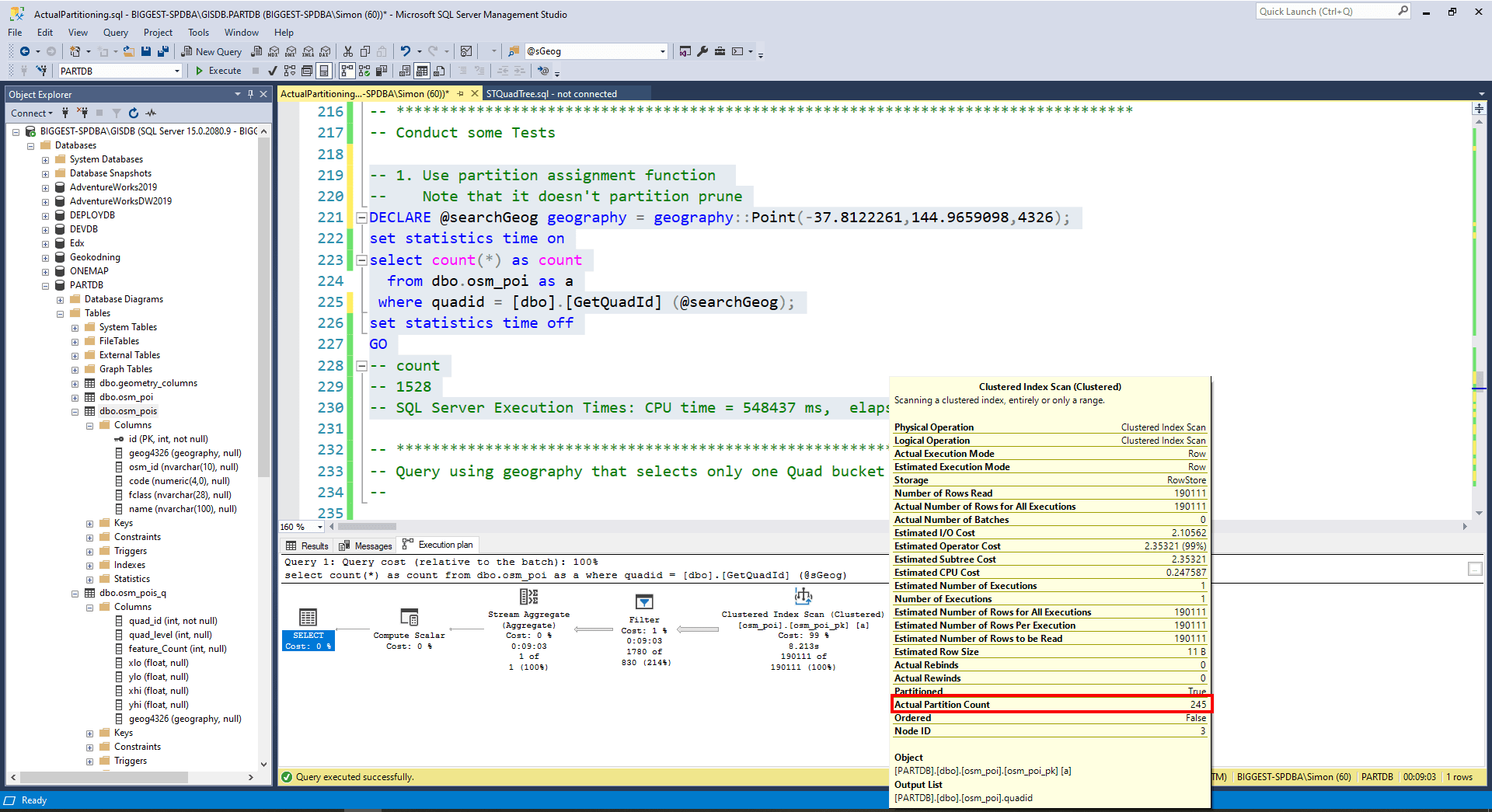
2. Query Quad Tree table using geography to select which Quad cell the search geography lies within
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326); DECLARE @sDist float = 10.0; SELECT a.quad_id as quadid FROM [dbo].[osm_pois_q] as a WHERE a.geog4326.STIntersects(@searchGeog.STBuffer(@sDist)) = 1; GO -- quadid -- 87 (one partition will be associated with the search geometry)
So, if we use this search geography we expect only partition 87 will be selected.
3. Query using quadid partition id found by search geography and conduct additional spatial filtering
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326);
DECLARE @searchDistance float = 10.0;
set statistics time on
select count(*) as count
from dbo.osm_poi as a
where a.quadid IN (SELECT a.quad_id
FROM [dbo].[osm_pois_q] as a
WHERE a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1)
AND a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1;
set statistics time off
— count
— 1
— SQL Server Execution Times: CPU time = 31 ms, elapsed time = 45 ms.
GO
Note in the following image how the query selected a single partition (Actual Partition Count of 1).

4. Now query only using spatial filter (No reference to partition id, causes reading of all 245 partitions).
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326); DECLARE @searchDistance float = 10.0; set statistics time on SELECT COUNT(*) FROM dbo.osm_poi as a WHERE a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1; set statistics time off -- 1 rows -- SQL Server Execution Times: CPU time = 4050 ms, elapsed time = 625 ms. GO
This query forced consideration of all partitions (see next), but ran in about a 10th the time of the single partition query. Note that it does not invoke the spatial index.

5. Query crossing two Quad buckets
5.1 Reference original quad polygon – partition prunes.
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326);
DECLARE @searchDistance float = 500.0;
SELECT a.quad_id
FROM [dbo].[osm_pois_q] as a
WHERE a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1;
GO
-- 87 and 88
-- 5.2 Execute partitioning query
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326);
DECLARE @searchDistance float = 500.0;
set statistics time on
select count(*)
from dbo.osm_poi as a
where a.quadid IN (SELECT a.quad_id
FROM [dbo].[osm_pois_q] as a
WHERE a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1
)
AND a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1;
set statistics time off
GO
-- 984 rows
-- SQL Server Execution Times: CPU time = 64 ms, elapsed time = 44 ms.
In the following execution plan (for query 5.2) we can see that it only considers 2 partitions (associated with quadid 87 and 88) and does not use the spatial index.

Forcing Spatial Index Use
The execution plans of the queries above show that none of them used the spatial index (osm_poi_sx) defined on osm_poi. It would appear that SQL Server decided not to apply the spatial index on the selected partitions. One wonders if partitions with much, much larger row counts might look at calling the spatial index after the partition pruning?
Forcing the use of the spatial index without partition selection returns acceptable performance even though the query optimizer has to consider all the partitions.
DECLARE @searchGeog geography = geography::Point(-37.8122261,144.9659098,4326); DECLARE @searchDistance float = 500.0; set statistics time on SELECT COUNT(*) as cnt FROM dbo.osm_poi as a WITH (INDEX([osm_poi_sx])) WHERE a.geog4326.STIntersects(@searchGeog.STBuffer(@searchDistance)) = 1; set statistics time off GO -- cnt -- 984 -- SQL Server Execution Times: CPU time = 78 ms, elapsed time = 84 ms.
This time it uses the spatial index and all 245 partitions. The fast performance of the query (still slightly slower than the partitioning query) is probably to do with candidate features being pruned in the spatial index processing before the data in the table is accessed.
Forcing spatial index use (WITH (INDEX([osm_poi_sx]))) in the dual partition query (5.2) above shows that the spatial index still appears to consume all 245 partitions and not the two selected partitions.
Conclusion
The cursory analysis conducted in this article indicates that partitioning spatial data, using a quad tree tesselation approach, can improve the performance of spatial queries. Deeper analysis is still needed on a much larger dataset to see if spatial indexing is ever invoked on partitioned queries.
This article did not consider the other benefits of partitioning..